


Một nhóm các nhà khoa học máy tính và nhà nghiên cứu AI từ FAIR tại Meta, INRIA, Đại học Paris Saclay và Google, đã phát triển một phương tiện khả thi để tự động hóa việc quản lý dữ liệu nhằm đào tạo trước các bộ dữ liệu AI tự giám sát.
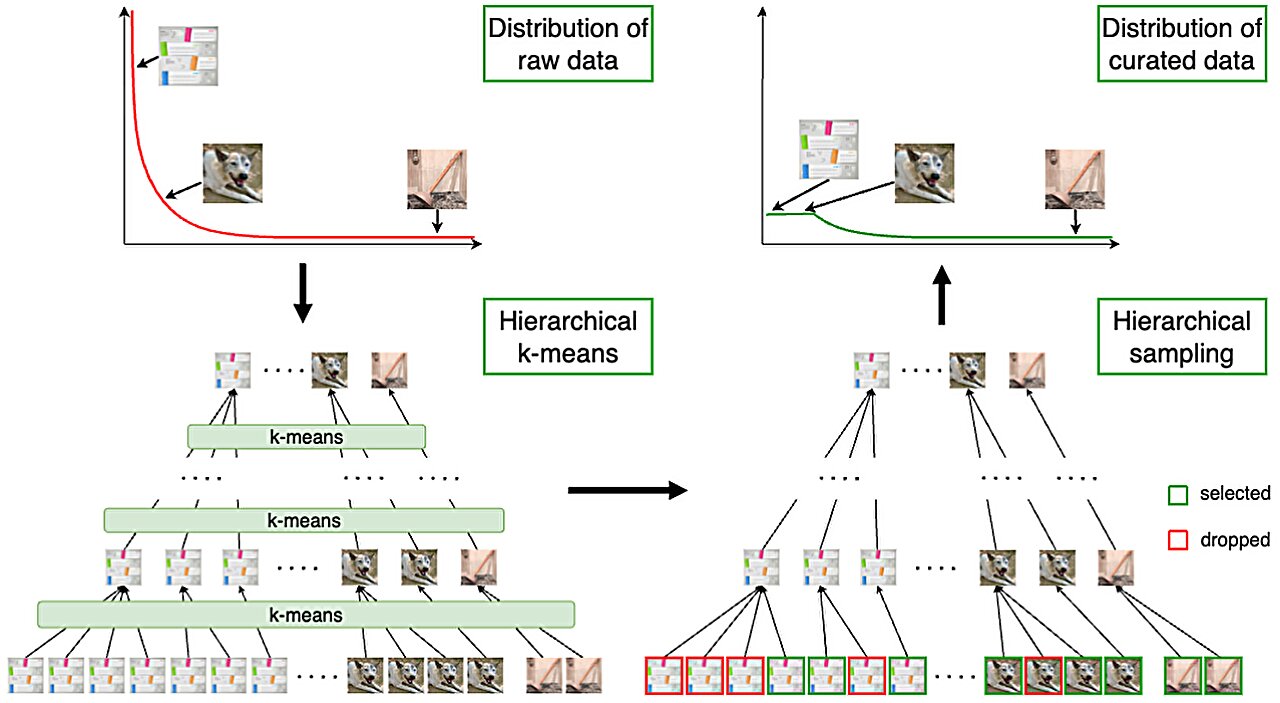
Tổng quan về đường ống quản lý dữ liệu. Nhóm dữ liệu lớn thường thể hiện sự phân bố dài hạn của các khái niệm. Chúng tôi áp dụng phương tiện k phân cấp để thu được các cụm trải đều trên các khái niệm. Sau đó, các điểm dữ liệu được lấy mẫu từ các cụm để tạo thành một tập dữ liệu được quản lý có sự cân bằng tốt hơn về các khái niệm. Nhà cung cấp: arXiv (2024). DOI: 10.48550/arxiv.2405.15613
Nhóm đã viết một bài báo mô tả quá trình phát triển của họ, kỹ thuật họ đã phát triển và nó đã hoạt động tốt như thế nào trong quá trình thử nghiệm. Nó được đăng trên máy chủ in sẵn arXiv.
Như các nhà phát triển cũng như người dùng đã tìm hiểu trong năm qua, chất lượng dữ liệu được sử dụng để đào tạo hệ thống AI gắn liền rất chặt chẽ với độ chính xác của kết quả. Hiện tại, kết quả tốt nhất thu được với các hệ thống sử dụng dữ liệu được quản lý thủ công và kết quả tệ nhất thu được từ các hệ thống không được quản lý.
Thật không may, việc quản lý dữ liệu theo cách thủ công tốn rất nhiều thời gian và công sức. Vì vậy, các nhà khoa học máy tính đã tìm cách tự động hóa quy trình. Trong nghiên cứu mới này, nhóm nghiên cứu đã phát triển một kỹ thuật thực hiện được điều đó và thực hiện nó theo cách ngang bằng với việc quản lý thủ công.
Kỹ thuật mới bắt đầu với một tập dữ liệu lớn, sau đó thực hiện quy trình ba bước để tạo ra dữ liệu đa dạng hơn và cân bằng hơn.
Bước đầu tiên liên quan đến việc sử dụng mô hình trích xuất đặc trưng để tính toán các vị trí chất lượng cao để nhúng các điểm dữ liệu. Theo cách tiếp cận của họ, những thứ được nhúng là những con số đại diện cho các đặc điểm của các loại dữ liệu khác nhau, chẳng hạn như văn bản, âm thanh hoặc hình ảnh.
Bước thứ hai liên quan đến việc sử dụng phân cụm k-mean liên tiếp, trong đó các điểm dữ liệu được gán cho một nhóm dựa trên mức độ tương tự của chúng với các điểm dữ liệu khác.
Bước thứ ba liên quan đến việc sử dụng phân cụm k-mean phân cấp nhiều bước để đảm bảo rằng các cụm dữ liệu được cân bằng. Nó đạt được thông qua việc xây dựng cây cụm dữ liệu theo kiểu từ dưới lên.
Nhóm nghiên cứu đã thử nghiệm kỹ thuật của họ bằng cách sử dụng các mô hình thị giác đã được đào tạo trên nhiều loại bộ dữ liệu khác nhau. Họ phát hiện ra rằng các mô hình sử dụng kỹ thuật của họ hoạt động tốt hơn những mô hình sử dụng dữ liệu chưa được quản lý và tốt bằng hoặc đôi khi tốt hơn những mô hình được đào tạo về dữ liệu được quản lý thủ công.
Sẽ phải thực hiện nhiều thử nghiệm hơn để tìm hiểu xem kỹ thuật của họ hoạt động tốt như thế nào trên dữ liệu trong thế giới thực và các loại hệ thống AI khác nhau.
Mời đối tác xem hoạt động của Công ty TNHH Pacific Group.
FanPage: https://www.facebook.com/Pacific-Group
YouTube: https://www.youtube.com/@PacificGroupCoLt






